Writing the fastest GBDT library in Rust

ModelFox makes it easy to train, deploy, and monitor machine learning models. With ModelFox, developers can train models and make predictions on the command line or with libraries for languages including Elixir, Golang, Javascript, PHP, Python, Ruby, and Rust, and learn about their models and monitor them in production from a web application. Watch the demo on the homepage.
In this post, we will go over how we optimized our Gradient Boosted Decision Tree library. This is based on a talk that we gave at RustConf 2021: Writing the Fastest Gradient Boosted Decision Tree Library in Rust. The code is available on GitHub.
The content of this post is organized into following sections:
- What are GBDTs.
- Use Rayon to Parallelize.
- Use cargo-flamegraph to find bottlenecks.
- Use cargo-asm to identify suboptimal code generation.
- Use intrinsics to optimize for specific CPUs.
- Use unsafe code to eliminate unnecessary bounds checks.
- Use unsafe code to parallelize non-overlapping memory access.
GBDT stands for Gradient Boosted Decision Tree. GBDTs are a type of machine learning model that perform incredibly well on tabular data. Tabular data is data that you would normally find in a spreadsheet or csv.
In order to get a feeling for how GBDT’s work, let’s go through an example of making a prediction with a single decision tree. Let’s say you want to predict the price of a house based on features like the number of bedrooms, bathrooms, and square footage. Here is a table with 3 features num_bedrooms, num_bathrooms and sqft. The final column called price is what we are trying to predict.
| num_bedrooms | num_bathrooms | sqft | price |
|---|---|---|---|
| 2 | 2 | 1200 | $300k |
| 4 | 3.5 | 2300 | $550k |
| 3 | 3 | 2200 | $450k |
| 8 | 9 | 7000 | $990k |
To make a prediction with a decision tree, you start at the top of the tree, and at each branch you ask how one of the features compares with a threshold. If the value is less than or equal to the threshold, you go to the left child. If the value is greater, you go to the right child. When you reach a leaf, you have the prediction.
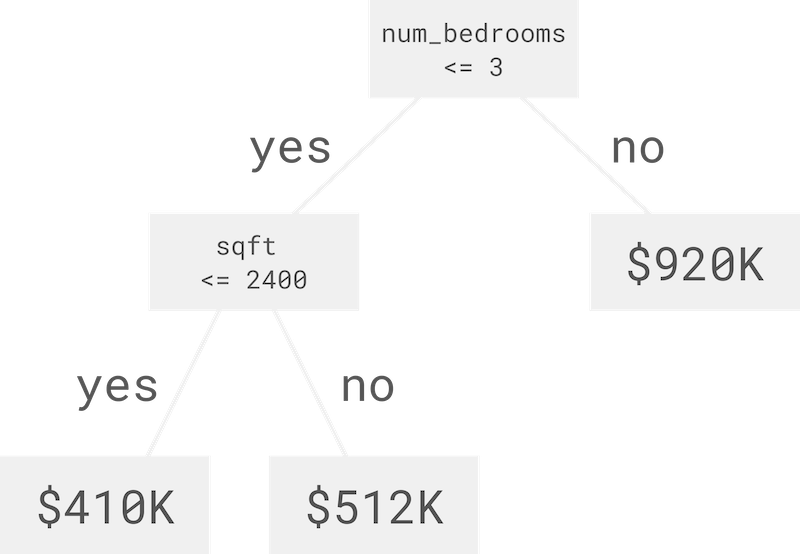
Let’s make an example prediction. We have a house with 3 bedrooms, 3 bathrooms, and 2500 square feet. Let’s see what price our decision tree predicts.
| num_bedrooms | num_bathrooms | sqft | price |
|---|---|---|---|
| 3 | 3 | 2500 | ? |
Starting at the top, the number of bedrooms is 3 which is less than or equal to 3, so we go left. The square footage is 2500 which is greater than 2400, so we go right, and we arrive at the prediction which is $512K.
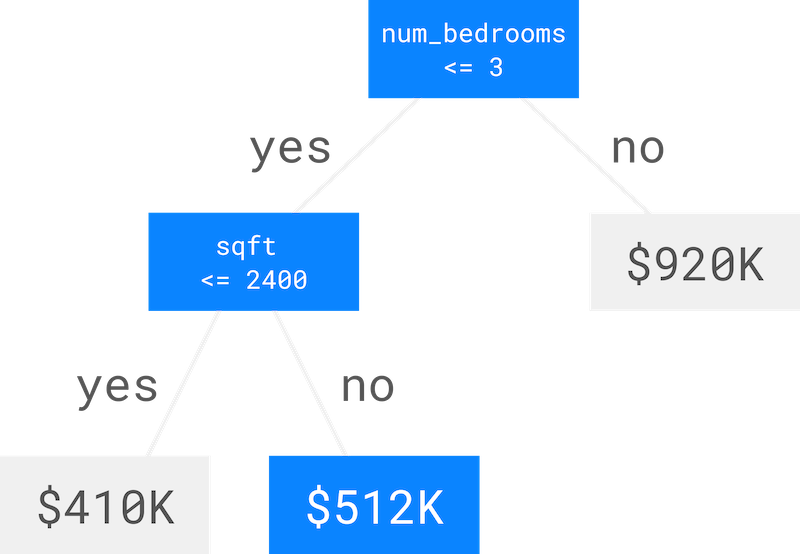
A single decision tree isn’t very good at making predictions on its own, so we train a bunch of trees, one at a time, where each tree predicts the error in the sum of the outputs of the trees before it. This is called gradient boosting over decision trees!
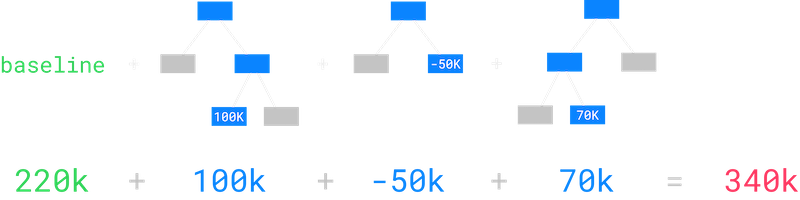
Making a prediction with gradient boosted decision trees is easy. We start with a baseline prediction which in the case of regression (predicting a continuous value like the price of a home) is just the average price of houses in our dataset. Then, we run the process we described for getting a prediction out of a single decision tree for each tree and sum up the outputs. In this example, the prediction is $340K.
To learn more about GBDT’s check out the wikipedia article on gradient boosting.
So now that we know a little about GBDT’s, let’s talk about how we made our code fast. The first thing we did was parallelize our code. Rayon makes this really easy. Rayon is a data parallelism library for Rust that makes converting sequential operations into parallel ones extremely easy.

The process of training trees takes in a matrix of training data which is n_rows by n_features.
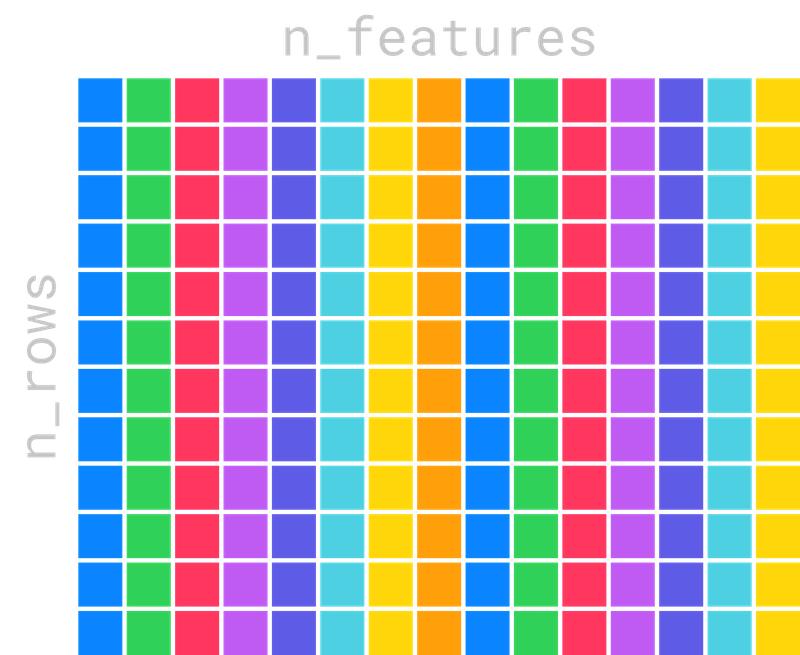
To decide which feature to use at each node, we need to compute a score for each feature. We do this by iterating over each column in the matrix. The following is a sequential iteration over the columns.
We can parallelize this code with Rayon. All we have to do is change the call to iter to par_iter.
Rayon will keep a thread pool around and schedule items from your iterator to be processed in parallel. Parallelizing over the features works well when the number of features is larger than the number of cores on your computer. When the number of features is smaller than the number of logical cores in your computer, parallelizing over the features is not as efficient. This is because some of our cores will be sitting idle so we will not be using all of the compute power available to us. You can see this clearly in the image below. Cores 1 through 4 have work to do because they have features 1 through 4 assigned to them. Cores 5 through 8 though are sitting idle.
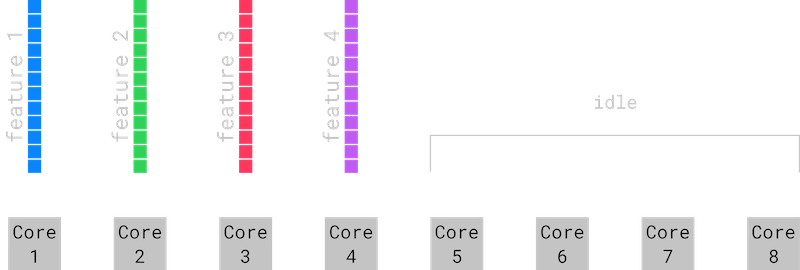
In this situation, we can parallelize over chunks of rows instead and make sure we have enough chunks so that each core has some work to do.
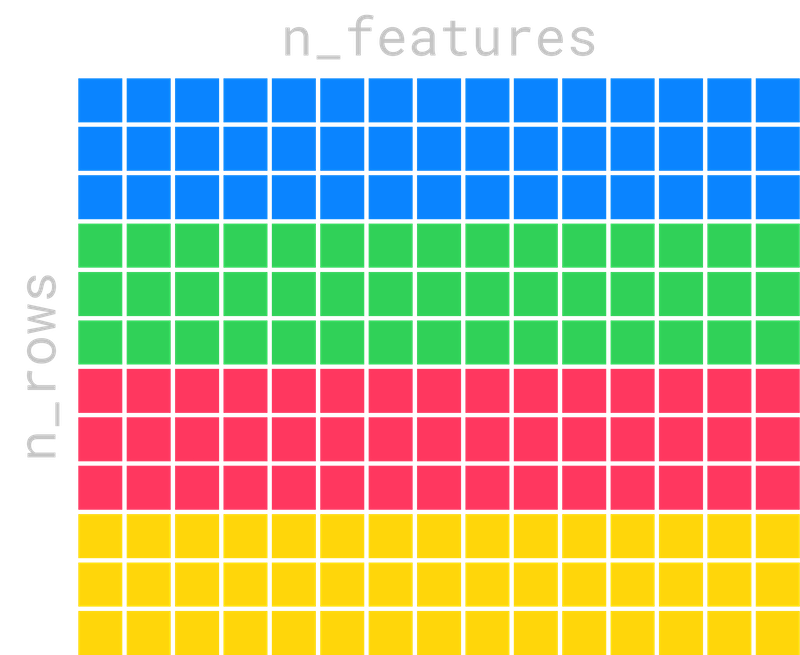
Each core now has some rows assigned to it, and no core is sitting idle.

Distributing the work across rows is super easy with Rayon as well. We just use the combinator par_chunks!
These are just a couple of the combinators available in Rayon. There are a lot of other high-level combinators that make it easy to express complex parallel computations. Check out Rayon on GitHub to learn more.
Next, we used cargo-flamegraph to find where most of the time was being spent. Cargo-flamegraph makes it easy generate flamegraphs and integrates elegantly with cargo. You can install it with cargo install, then run cargo flamegraph to run your program and generate a flamegraph.
Here is a simple example with a program that calls two subroutines, foo and bar.
When we run cargo flamegraph we get an output that looks like this.
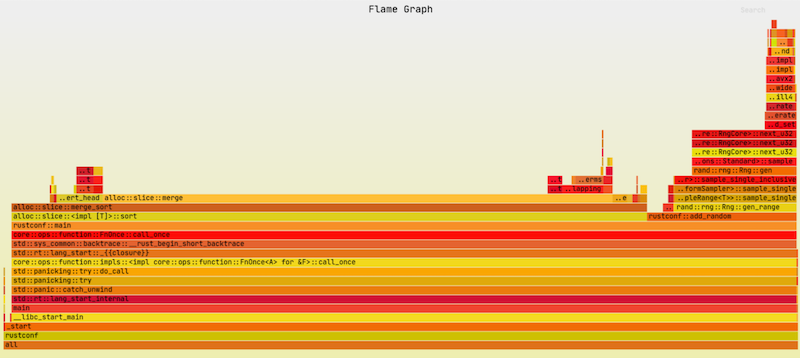
It contains a lot of extra functions that you have to sort through, but it boils down to something like this.
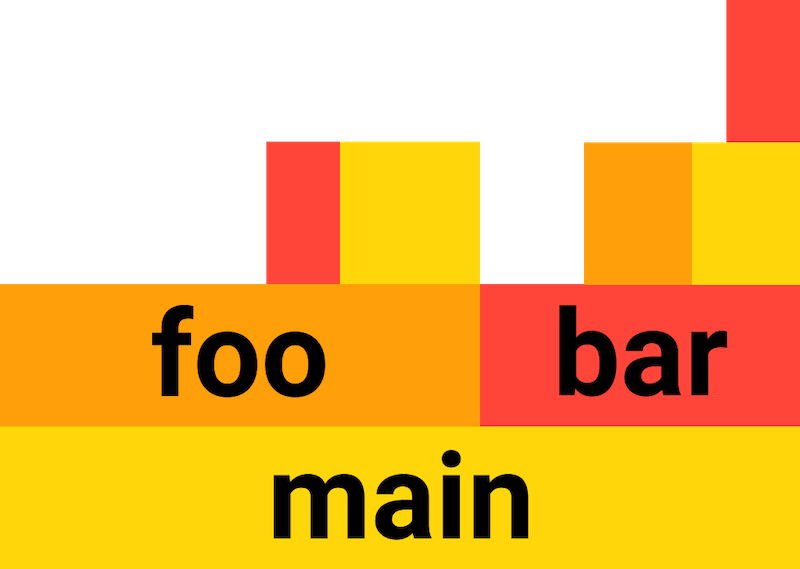
The y-axis of the graph is the call stack, and the x axis is duration. The bottom of the graph shows that the entire duration of the program was spent in the main function. Above that, you see that the main function’s time is broken up between calls to foo and bar, and that about two thirds of the time was spent in foo and its subroutines and about one third of the time spent in bar and its subroutines.
In our code for training decision trees, the flamegraph showed one function where the majority of the time was spent. In this function, we maintain an array of the numbers 0 to n that we call indexes, and at each iteration of training we rearrange it. Then, we access an array of the same length, called values, but in the order of the indexes in the indexes array.
This results in accessing each item in the values array out of order. We will refer back to this function throughout the rest of this post.
From the flamegraph, we knew which function was taking the majority of the time, which we briefly described above. We started by looking at the assembly code it generated to see if there were any opportunities to make it faster. We did this with cargo-asm.
Like cargo-flamegraph, cargo-asm is really easy to install and integrates nicely with cargo. You can install it with cargo install, and run it as a cargo subcommand.
Here is a simple example with a function that adds two numbers and multiplies the result by two.
When we run cargo asm, we get an output that looks like this. It shows the assembly instructions alongside the rust code that generated them.
Note that due to all the optimizations the compiler does, there is often not a perfect correlation from the rust code to the assembly.
When we looked at the assembly for this loop, we were surprised to find an imul instruction, which is an integer multiplication.
What is that doing in our code? We are just indexing into an array of f32’s. f32’s are 4 bytes each, so the compiler should be able to get the address of the ith item by multiplying i * 4. Multiplying by four is the same as shifting i left by two. Shifting left by two is much faster than integer multiplication.
Why would the compiler not be able to produce a shift left instruction? Well, the values array is a column in a matrix and a matrix can be stored either in row major or column major order. This means that indexing into the column might require multiplying by the number of columns in the matrix, which is unknown at compile time. But since we were storing our matrix in column major order, we could eliminate the multiplication, but we have to convince the compiler of this.
We did this by casting the values array to a slice. This convinced the compiler that the values array was contiguous, so it could access items using the shift left instruction, instead of integer multiplication.
Next, we used compiler intrinsics to optimize for specific CPUs. Intrinsics are special functions that hint to the compiler to generate specific assembly code.
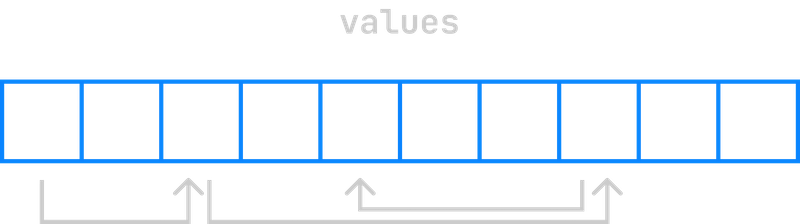
Remember how we noticed that this code results in accessing the values array out of order? This is really bad for cache performance, because CPUs assume you are going to access memory in order. If a value isn’t in cache, the CPU has to wait until it is loaded from main memory, making your program slower.
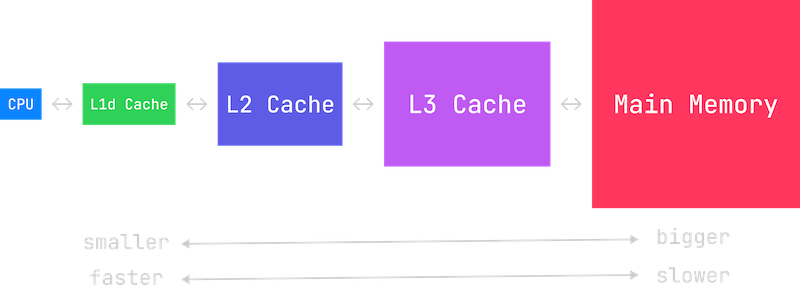
However, we know which values we are going to be accessing a few iterations of the loop in the future. We know this because the indexes are given by the indexes array. So 10 iterations in the future, we will be accessing values[indexes[current_index + 10]]. We can hint to x86_64 CPU’s to prefetch those values into cache using the mm_prefetch intrinsic. We experimented with different values of the OFFSET until we got the best performance. If the OFFSET is too small, the CPU will still have to wait for the data, if the OFFSET is too large, data that the CPU needs might be evicted and by the time the CPU gets to the iteration that needs the data, it will no longer be there. The best offset will vary depending on your computer’s hardware so it can be more of an art than a science.
If you are interested in cache performance and writing performant code, check out Mike Acton’s talk on Data-Oriented Design and Andrew Kelly’s recent talk at Handmade Seattle.
Next, we used a touch of unsafe to remove some unnecessary bounds checks.
Most of the time, the compiler can eliminate bounds checks when looping over values in an array. However, in this code, it has to check that index is within the bounds of the values array.
But we said at the beginning that the indexes array is a permutation of the values 0 to n. This means the bounds check is unnecessary. We can fix this by replacing get_mut with get_unchecked_mut. We have to use unsafe code here, because Rust provides no way to communicate to the compiler that the values in the indexes array are always in bounds of the values array.
Finally, we parallelized the following code:
But is it even possible to parallelize? At first glance, it seems the answer is no, because we are accessing the values array mutably in the body of the loop.
If we try it, the compiler will give us an error indicating overlapping borrows. However, the indexes array is a permutation of the values 0 to n, so we know that the access into the values array is never overlapping.
We can parallelize our code using unsafe Rust, wrapping a pointer to the values in a struct and unsafely marking it as Send and Sync.
So, going back to the code we started out with…
Finally, when combining the four optimizations together:
- Making sure that the values array is a contiguous slice.
- Prefetching values so they are in cache.
- Removing bounds checks because we know the indexes are always in bounds.
- Parallelizing over the indexes because we know they never overlap.
this is the code we get:
Here are our benchmarks on training time comparing ModelFox’s Gradient Boosted Decision Tree Library to LightGBM, XGBoost, CatBoost, and sklearn.
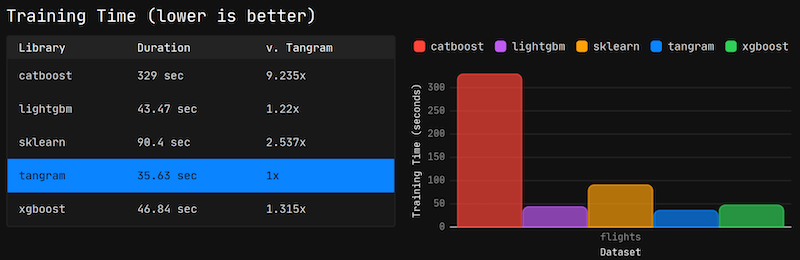
To see all the benchmarks, head over to https://modelfox.dev/benchmarks.
If you are interested in reading the code or giving us a star, the project is available on GitHub.